TEOS
Blocks World Revisited: The Effect of Self-Occlusion on Classification by Convolutional Neural Networks

Despite the recent successes in computer vision, there remain new avenues to explore. In this work, we propose a new dataset to investigate the effect of self-occlusion on deep neural networks.
With TEOS (The Effect of Self-Occlusion), we propose a 3D blocks world dataset that focuses on the geometric shape of 3D objects and their omnipresent self-occlusion. We designed TEOS to investigate the role of self-occlusion in the context of object classification. In the real-world, self-occlusion of 3D objects still presents significant challenges for deep learning approaches.
However, humans deal with this by deploying complex strategies, for instance, by changing the view-point or manipulating the scene to gather necessary information.
With TEOS, we present a dataset with two subsets (L1 and L2), containing 36 and 12 objects, respectively. We provide 768 uniformly sampled views of each object, their mask, object and camera position, orientation, amount of self-occlusion, as well as the CAD model of each object. We present baseline evaluations with five well-known classification deep neural networks and show that TEOS poses a significant challenge for all of them.
Video: Oral presentation at Real-World Computer Vision from Inputs with Limited Quality (RLQ) - In conjunction with ICCV 2021
TEOS Publication (arxiv.org)
Link to the associated publication
(please cite if you find any of this useful)
TEOS Dataset
L1 only
L2 only
The proposed Dataset containing 3D models, 738 uniformly sampled views of each object, including their mask, pose, and amount of self-occlusion.
TEOS pre-trained CNN models
L1 only
L2 only
Set of CNN models (Tensorflow), pre-trained on TEOS, used to evaluate this Dataset.
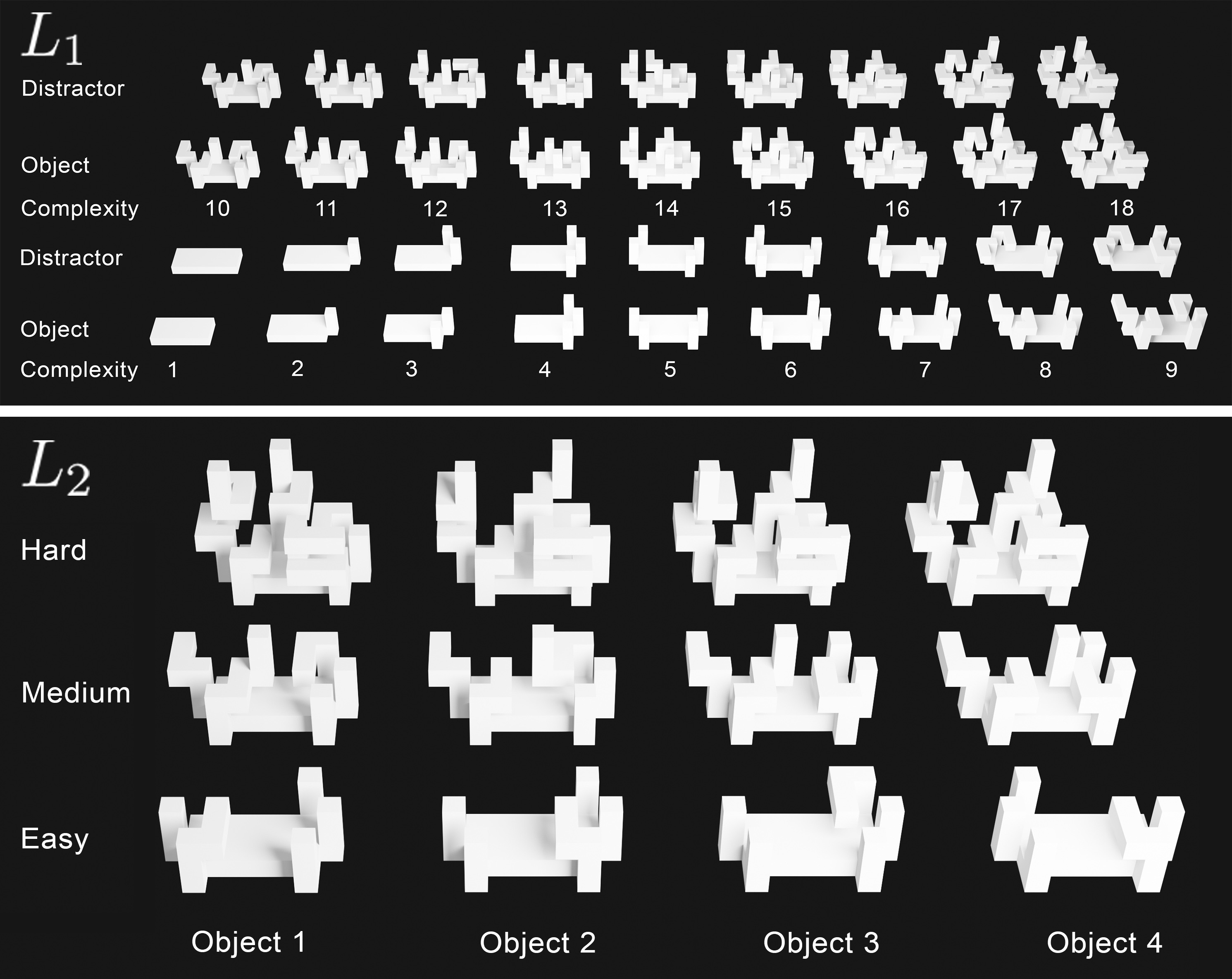
Top: Illustration of L1 with all 36 objects. Bottom: Illustration of L2 with all 12 objects, split into three different complexity classes.
In case you use this work in one of your publications, please make sure to cite us:
Solbach, Markus D., Tsotsos, John K. "Blocks World Revisited: The Effect of Self-Occlusion on Classification by Convolutional Neural Networks" Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops. 2021.
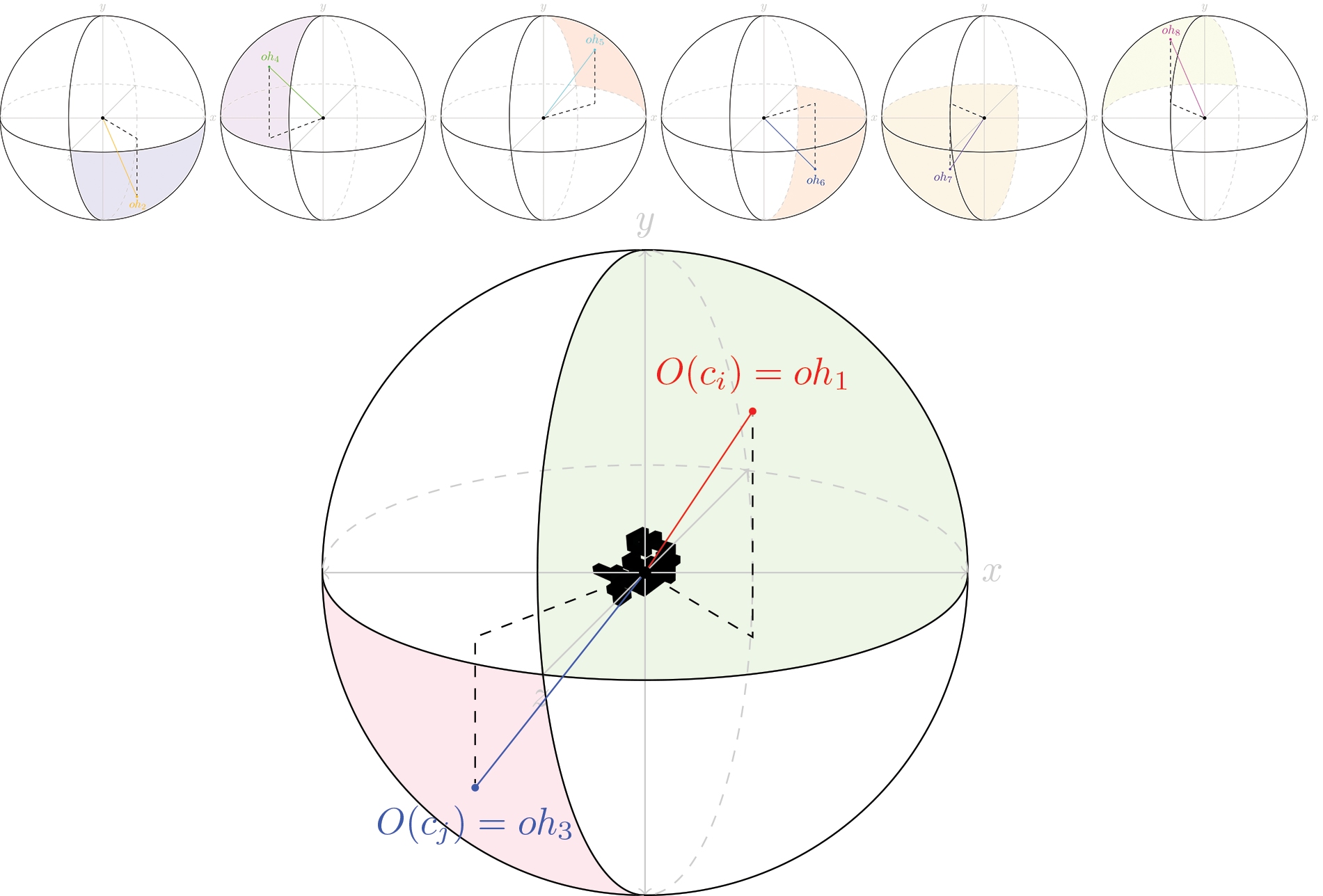
Visualization of the octahedron based projection used to map camera positions. Bottom: two example camera poses (ci and cj) mapped to oh1 and oh3.
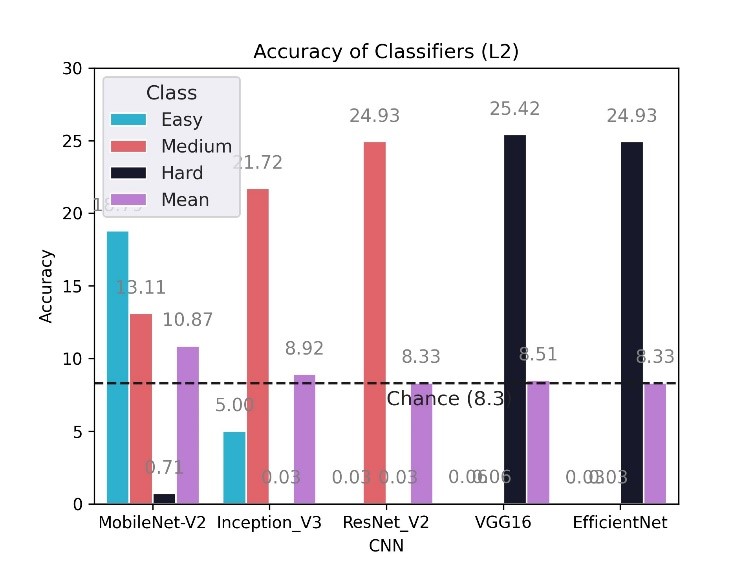
Accuracy of Classifiers on the L2 dataset.